Hugo发布
使用命令行,进入你博客目录,然后执行hugo就好了。比如:
1
2
3
|
D:
cd D:\OdinXu\odinxu-blog\
hugo
|
就能生成全部静态文件到默认目录 ./public/ 下面
可以带上 -D 参数,将草稿文章,也一起发布。
还可以用 -d path 参数,指定生成静态文件到哪一个目录。比如:
1
|
hugo -D -d ..\github-public\
|
生成好后,就可以把 public 目录下的全部文件,上传到阿里云OSS里面了。
使用阿里云OSS软件上传
阿里云OSS提供的软件有 OSSBrowser, OSSUtil,在后台可以下载使用:
OSSUtil用起来比较麻烦,最简单的是OSSBrowser,如下图:
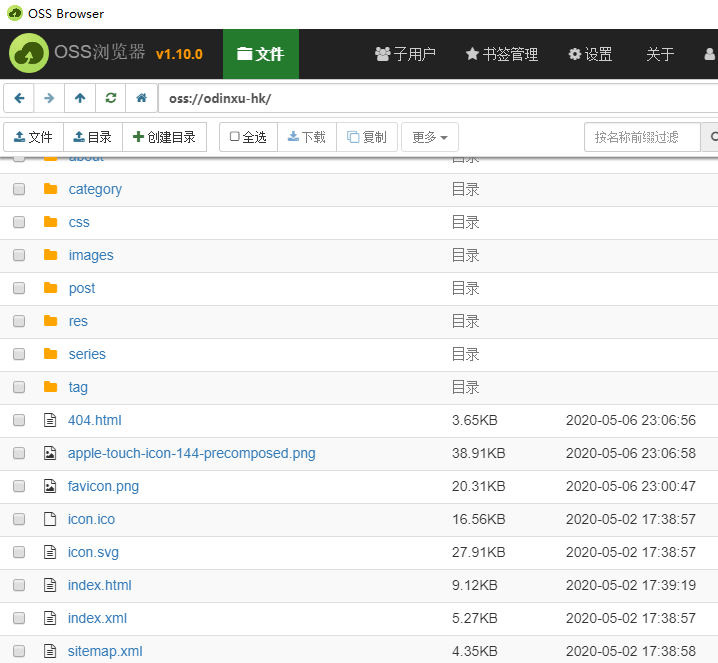
登录后,在Windows里可以直接复制粘贴(或者直接拖动进去)就能上传文件,就跟Windows文件资源管理器操作体验一样。
不过,如果你的博客文章已经很多了,或者说经常更新内容,总不能每次都全站重新上传一次吧。或者每次需要更新上传哪几个文件,自己慢慢找,再分别一个个传到对应的目录去?
这样太麻烦了。
正好阿里云是有开放SDK,我们可以写个Python3程序来自动做这个事。
阿里云的SDK有很多种,详见这里
1
2
3
4
5
6
7
8
9
10
11
12
13
|
Android
iOS
Java
.Net
PHP
Python
Ruby
C
Go
Javascript
NodeJS
Media
React Native
|
安装阿里云的Python SDK
Python SDK的使用说明详见:阿里云OSS云存储的Python SDK
编写Python3程序
Python3程序代码大约130行,完整程序代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
|
import os
import time
import json
import hashlib
import requests
import oss2
from concurrent.futures import ThreadPoolExecutor, as_completed
OSS_CONFIG_accessKeyId = "替换为你的accessKeyId"
OSS_CONFIG_accessKeySecret = "替换为你的OSS_CONFIG_accessKeySecret"
OSS_CONFIG_endpoint = "替换为你的endpoint,类似这样 oss-cn-hongkong.aliyuncs.com"
OSS_CONFIG_bucketName = "替换为你的bucketName"
OSS_CONFIG_localDir = "替换为你的本地路径,类似这样 D:/OdinXu/odinxu-blog/public/"
# 注意 localDir 必须 / 结尾
MAX_THREAD_COUNT = 10
MD5_CACHE_FILE = "local_file_md5.cache"
md5dict = {}
#计算文件的md5值
def file_md5(filename):
myhash = hashlib.md5()
f = open(filename,'rb')
while True:
b = f.read(8096)
if not b :
break
myhash.update(b)
f.close()
return myhash.hexdigest()
# 使用SDK API接口,检查OSS里是否存在文件,
# 然后检查object_meta的 ETag 值
# 跟本地文件计算的 file_md5 值是否相同
# 来决定,要不要上传文件
def sync_local_file_to_aliyun_oss(local_filename):
if local_filename.endswith('.DS_Store') or not os.path.isfile(local_filename):
return "...skip...: " + local_filename
oss_object_key = local_filename[len(OSS_CONFIG_localDir):]
# print(oss_object_key)
cur_file_md5 = file_md5(local_filename)
global md5dict
md5dict[local_filename] = cur_file_md5
up = False
if bucket.object_exists(oss_object_key):
filemeta = bucket.get_object_meta(oss_object_key)
if filemeta.headers['ETag'].lower().strip('"') != cur_file_md5:
up = True
else:
up = True
if up:
print('uploading: ' + local_filename)
result = bucket.put_object_from_file(oss_object_key, local_filename)
if result.status != 200:
md5dict[local_filename] = 'upload error'
return 'upload error, response information: ' + str(result)
else:
return "Up new ok : " + oss_object_key
else:
return "...fit... : " + oss_object_key ##不需要上传文件,因为md5相同
#本地哪一些文件的md5值,跟本地cache文件保存的md5值不相同
#决定和OSS对比文件前,先自己本地md5对比一下,这样速度快。
def find_diff_md5_local_file(files):
global md5dict
if os.access(MD5_CACHE_FILE, os.F_OK):
try:
f=open(MD5_CACHE_FILE,'r')
md5dict = json.load(f)
except:
md5dict = {}
# print(md5dict)
result = []
for file in files:
md5c = md5dict.get(file)
if (md5c== None) or (file_md5(file) != md5c):
result.append(file)
return result
if __name__ == '__main__':
time_start=time.time()
is_windows = (os.name == 'nt')
files = []
for dirpath, dirnames, filenames in os.walk(OSS_CONFIG_localDir):
for filename in filenames:
local_filename = os.path.join(dirpath, filename)
if is_windows:
local_filename = local_filename.replace('\\', '/')
files.append(local_filename)
time_end1=time.time()
print('查找本地文件:{:.4f}秒'.format(time_end1-time_start))
print("本地文件数量:{}个".format(len(files)))
files = find_diff_md5_local_file(files)
fCount = len(files)
print("需要OSS同步的文件数量:{}".format(fCount))
if fCount==0:
print("程序结束,无需同步。(删除.cache文件可强制进行OSS文件同步)")
exit(0)
auth = oss2.Auth(OSS_CONFIG_accessKeyId, OSS_CONFIG_accessKeySecret)
bucket = oss2.Bucket(auth, OSS_CONFIG_endpoint, OSS_CONFIG_bucketName)
time_end2=time.time()
print('登录OSS:{:.4f}秒'.format(time_end2-time_end1))
fCurrent = 0
print("启动{}个线程进行同步".format(MAX_THREAD_COUNT))
executor = ThreadPoolExecutor(max_workers=MAX_THREAD_COUNT)
all_task = [executor.submit(sync_local_file_to_aliyun_oss, (file)) for file in files]
for future in as_completed(all_task):
fCurrent += 1
data = future.result()
print("{}/{}\t: {}".format(fCurrent,fCount,data))
time_end3=time.time()
print('同步完全部文件:{:.4f}秒'.format(time_end3-time_end2))
# print("md5dict len:", len(md5dict))
# print(md5dict)
if len(md5dict)>0:
try:
f=open(MD5_CACHE_FILE,'w')
json.dump(md5dict,f)
except:
print("Save md5 cache faild.")
time_end_all=time.time()
print('程序全部时间:{:.4f}秒'.format(time_end_all-time_start))
|
程序的运行效果,如下图:
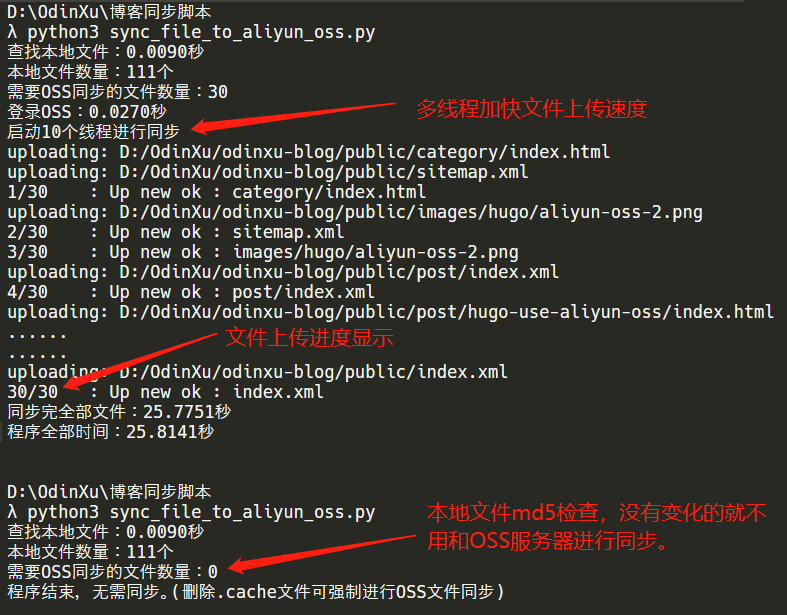
写个脚本来自动化
将上面的Python3程序保存为 sync_file_to_aliyun_oss.py ,然后再新建一个脚本 start_sync_blog_to_oss.bat,文件内容如下:
1
2
3
4
5
6
|
D:
cd D:\OdinXu\odinxu-blog\
hugo
cd D:\OdinXu\博客同步脚本\
python3 sync_file_to_aliyun_oss.py
pause
|
就完成了。每次你写完文章要发布了,就点击一下这个bat脚本,全自动搞定。


